
1. Overview
In this article, we introduce the steps for visualizing the operating status of NVIDIA GPUs using NVIDIA’s DCGM Exporter together with Prometheus and Grafana.
DCGM (Data Center GPU Manager) is a toolkit for monitoring and managing GPUs, and by using DCGM Exporter you can obtain metrics in Prometheus format.
Of course, you can also monitor GPU status with the nvidia-smi command.
However, relying solely on nvidia-smi has the following limitations:
The method presented here eliminates these drawbacks and enables centralized monitoring in Grafana.
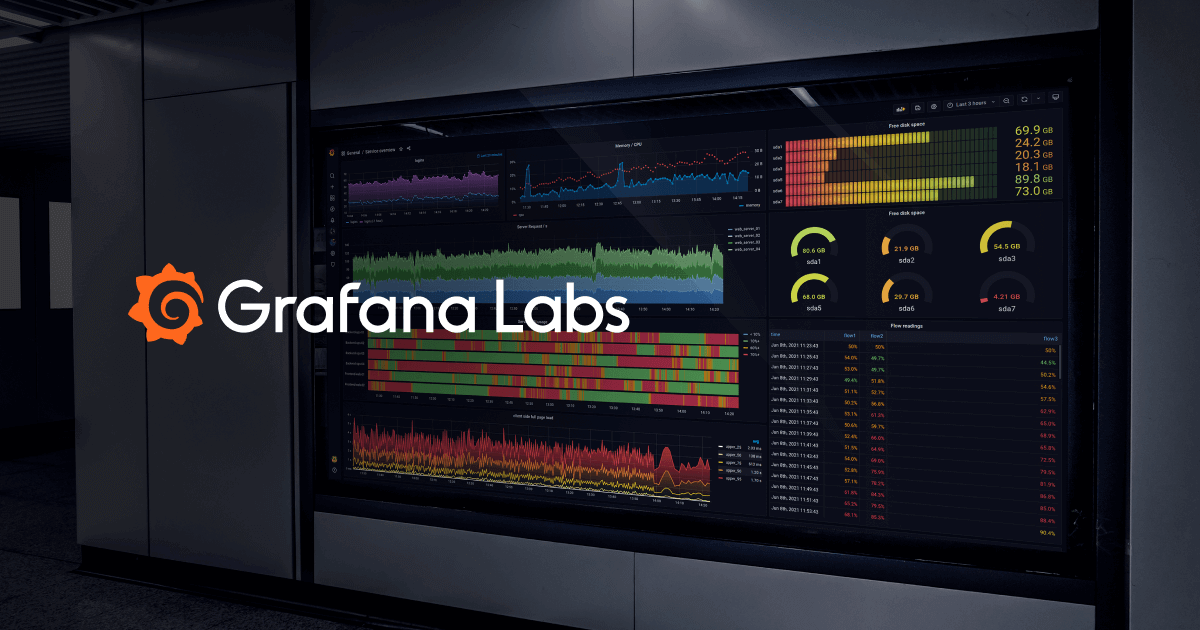
When finished, you will be able to check GPU usage on a Grafana dashboard like the one below.

2. Intended Readers
3. Configuration and Prerequisites
We will build a two‑node setup consisting of a GPU server and a monitoring server.
※ For small test environments, you can place both containers on the GPU server.
The flow of communication during operation is illustrated below.

4. GPU Server: Setting Up DCGM Exporter
First, set up DCGM Exporter on the GPU server.
For further background, see the official manual.
4.1 Verify NVIDIA Container Toolkit Installation
Ensure that NVIDIA Container Toolkit is installed on the GPU server:
dpkg -l | grep nvidia-container-toolkit
Expected output:
ii nvidia-container-toolkit 1.17.5-1 amd64 NVIDIA Container toolkit
ii nvidia-container-toolkit-base 1.17.5-1 amd64 NVIDIA Container Toolkit Base
4.2 Pull and Run DCGM Exporter
DCGM Exporter is provided as a container image in the NVIDIA NGC Catalog. No API key is required for this public image.
docker pull nvcr.io/nvidia/k8s/dcgm-exporter:4.2.3-4.1.3-ubuntu22.04
Start the container (be sure to set the two options below):
docker run -d --rm \
--gpus all \
--cap-add SYS_ADMIN \
-p 9400:9400 \
--name dcgm-exporter \
nvcr.io/nvidia/k8s/dcgm-exporter:4.2.3-4.1.3-ubuntu22.04
Verify that the container is running:
docker ps -f name=dcgm-exporter
Expected output (example):
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
462dde910a54 nvcr.io/nvidia/k8s/dcgm-exporter:4.2.3-4.1.3-ubuntu22.04 "/usr/local/dcgm/dcg…" 10 seconds ago Up 9 seconds 0.0.0.0:9400->9400/tcp dcgm-exporter
Confirm Metrics Endpoint
curl http://localhost:9400/metrics | head -n 5
Expected output (example):
# HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz).
# TYPE DCGM_FI_DEV_SM_CLOCK gauge
DCGM_FI_DEV_SM_CLOCK{gpu="0",UUID="GPU-f8291959-100f-80a2-a0e5-3db0f7f94746",pci_bus_id="00000000:1B:00.0",device ="nvidia0",modelName="NVIDIA H200",Hostname="462dde910a54",DCGM_FI_DRIVER_VERSI ON="570.124.06"} 345
5. Monitoring Server: Prometheus & Grafana Setup
5.1 Create Persistent Data Directories
Prometheus and Grafana use fixed internal UIDs/GIDs. Create the directories and set ownership:
sudo mkdir -p /opt/prometheus/data
sudo mkdir -p /opt/grafana/data
sudo chown -R 65534:65534 /opt/prometheus/data # Prometheus UID/GID
sudo chown -R 472:472 /opt/grafana/data # Grafana UID/GID
5.2 Create Prometheus Configuration File
Create prometheus.yml in the same directory as your future docker-compose.yml:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'dcgm-exporter'
static_configs:
- targets: [':9400']
5.3 Launch Prometheus & Grafana via Docker Compose
Pull the images:
docker pull prom/prometheus:v3.4.1
docker pull grafana/grafana:12.0.1
Next, prepare the contents for starting Prometheus and Grafana in docker-compose.yml.
Basically, you will write down the contents you have prepared up to this point.
services:
prometheus:
image: prom/prometheus:v3.4.1
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- /opt/prometheus/data:/prometheus
ports:
- "9090:9090"
grafana:
image: grafana/grafana:12.0.1
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=
volumes:
- /opt/grafana/data:/var/lib/grafana
Notes:
Start the stack:
docker compose up -d
Verify that the container is running:
docker compose ps
Expected output (example):
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
prometheus prom/prometheus:v3.4.1 "/bin/prometheus --c…" prometheus 2 minutes ago Up 2 minutes 0.0.0.0:9090->9090/tcp
grafana grafana/grafana:12.0.1 "/run.sh" grafana 2 minutes ago Up 2 minutes 0.0.0.0:3000->3000/tcp
5.4 Confirm Prometheus Targets
Open a browser at http://:9090/targets.
You should see dcgm-exporter listed with state UP.

5.5 Log In to Grafana
Access http://:3000 and the login screen will appear. Log in with admin / (or admin / admin if the variable was omitted).

When login succeeds, Grafana is running correctly.

6. Create Grafana Dashboard
We will use NVIDIA’s published template below.
6.1 Add Prometheus as a Data Source
From the Grafana console, open Add new connection and select Prometheus.

Enter http://:9090 in the Connection field, then Save & Test.

6.2 Import the Dashboard Template
Open Dashboards → New → import.

Because we are using a public template, enter 12239 as the template ID and click Load.

If the dashboard imports successfully, GPU temperature, utilization, memory bandwidth, and more will be visualized in real time.

7. Summary
We visualized GPU usage using DCGM Exporter.
Although only one GPU server was used here, you can register multiple servers in Prometheus and manage them together in Grafana.
For very small setups, running Prometheus and Grafana directly on the GPU server is also an option.
8. Extras
Although not covered in detail, the following are useful from an operations perspective.
9. References
More...
In this article, we introduce the steps for visualizing the operating status of NVIDIA GPUs using NVIDIA’s DCGM Exporter together with Prometheus and Grafana.
DCGM (Data Center GPU Manager) is a toolkit for monitoring and managing GPUs, and by using DCGM Exporter you can obtain metrics in Prometheus format.
Of course, you can also monitor GPU status with the nvidia-smi command.
However, relying solely on nvidia-smi has the following limitations:
- Manual polling — you need to loop it with a shell script, for example
- Difficult to centrally monitor multiple hosts — logging in to each host via SSH is cumbersome
- No long‑term time‑series data — CSV logging is possible but not easy to visualize
The method presented here eliminates these drawbacks and enables centralized monitoring in Grafana.
When finished, you will be able to check GPU usage on a Grafana dashboard like the one below.
2. Intended Readers
- Those interested in visualizing resource usage on GPU‑equipped machines
- Those who want to try collecting metrics with DCGM Exporter / Prometheus / Grafana
- Those who want to build a GPU monitoring stack using Docker
3. Configuration and Prerequisites
We will build a two‑node setup consisting of a GPU server and a monitoring server.
| GPU server | Target GPU server to be monitored; runs DCGM Exporter | Ubuntu 24.04 | Present | Docker, NVIDIA Container Toolkit |
| Monitoring server | Runs Prometheus and Grafana | Ubuntu 24.04 | None | Docker, Compose Plugin |
※ For small test environments, you can place both containers on the GPU server.
The flow of communication during operation is illustrated below.
4. GPU Server: Setting Up DCGM Exporter
First, set up DCGM Exporter on the GPU server.
For further background, see the official manual.
4.1 Verify NVIDIA Container Toolkit Installation
Ensure that NVIDIA Container Toolkit is installed on the GPU server:
dpkg -l | grep nvidia-container-toolkit
Expected output:
ii nvidia-container-toolkit 1.17.5-1 amd64 NVIDIA Container toolkit
ii nvidia-container-toolkit-base 1.17.5-1 amd64 NVIDIA Container Toolkit Base
4.2 Pull and Run DCGM Exporter
DCGM Exporter is provided as a container image in the NVIDIA NGC Catalog. No API key is required for this public image.
docker pull nvcr.io/nvidia/k8s/dcgm-exporter:4.2.3-4.1.3-ubuntu22.04
Start the container (be sure to set the two options below):
- --gpus all — only GPUs passed to the container are monitored
- --cap-add SYS_ADMIN — without this, some metrics cannot be collected
docker run -d --rm \
--gpus all \
--cap-add SYS_ADMIN \
-p 9400:9400 \
--name dcgm-exporter \
nvcr.io/nvidia/k8s/dcgm-exporter:4.2.3-4.1.3-ubuntu22.04
Verify that the container is running:
docker ps -f name=dcgm-exporter
Expected output (example):
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
462dde910a54 nvcr.io/nvidia/k8s/dcgm-exporter:4.2.3-4.1.3-ubuntu22.04 "/usr/local/dcgm/dcg…" 10 seconds ago Up 9 seconds 0.0.0.0:9400->9400/tcp dcgm-exporter
Confirm Metrics Endpoint
curl http://localhost:9400/metrics | head -n 5
Expected output (example):
# HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz).
# TYPE DCGM_FI_DEV_SM_CLOCK gauge
DCGM_FI_DEV_SM_CLOCK{gpu="0",UUID="GPU-f8291959-100f-80a2-a0e5-3db0f7f94746",pci_bus_id="00000000:1B:00.0",device ="nvidia0",modelName="NVIDIA H200",Hostname="462dde910a54",DCGM_FI_DRIVER_VERSI ON="570.124.06"} 345
5. Monitoring Server: Prometheus & Grafana Setup
5.1 Create Persistent Data Directories
Prometheus and Grafana use fixed internal UIDs/GIDs. Create the directories and set ownership:
sudo mkdir -p /opt/prometheus/data
sudo mkdir -p /opt/grafana/data
sudo chown -R 65534:65534 /opt/prometheus/data # Prometheus UID/GID
sudo chown -R 472:472 /opt/grafana/data # Grafana UID/GID
5.2 Create Prometheus Configuration File
Create prometheus.yml in the same directory as your future docker-compose.yml:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'dcgm-exporter'
static_configs:
- targets: [':9400']
- scrape_interval — monitoring frequency
- targets — IP address and port (9400) of the GPU server running DCGM Exporter
5.3 Launch Prometheus & Grafana via Docker Compose
Pull the images:
docker pull prom/prometheus:v3.4.1
docker pull grafana/grafana:12.0.1
Next, prepare the contents for starting Prometheus and Grafana in docker-compose.yml.
Basically, you will write down the contents you have prepared up to this point.
services:
prometheus:
image: prom/prometheus:v3.4.1
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- /opt/prometheus/data:/prometheus
ports:
- "9090:9090"
grafana:
image: grafana/grafana:12.0.1
container_name: grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=
volumes:
- /opt/grafana/data:/var/lib/grafana
Notes:
- Prometheus expects the file to be named prometheus.yml (extension yml).
- The value of GF_SECURITY_ADMIN_PASSWORD sets the initial password for user admin. If omitted, the default is admin.
Start the stack:
docker compose up -d
Verify that the container is running:
docker compose ps
Expected output (example):
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
prometheus prom/prometheus:v3.4.1 "/bin/prometheus --c…" prometheus 2 minutes ago Up 2 minutes 0.0.0.0:9090->9090/tcp
grafana grafana/grafana:12.0.1 "/run.sh" grafana 2 minutes ago Up 2 minutes 0.0.0.0:3000->3000/tcp
5.4 Confirm Prometheus Targets
Open a browser at http://:9090/targets.
You should see dcgm-exporter listed with state UP.
5.5 Log In to Grafana
Access http://:3000 and the login screen will appear. Log in with admin / (or admin / admin if the variable was omitted).
When login succeeds, Grafana is running correctly.
6. Create Grafana Dashboard
We will use NVIDIA’s published template below.
6.1 Add Prometheus as a Data Source
From the Grafana console, open Add new connection and select Prometheus.
Enter http://:9090 in the Connection field, then Save & Test.
6.2 Import the Dashboard Template
Open Dashboards → New → import.
Because we are using a public template, enter 12239 as the template ID and click Load.
If the dashboard imports successfully, GPU temperature, utilization, memory bandwidth, and more will be visualized in real time.
7. Summary
We visualized GPU usage using DCGM Exporter.
Although only one GPU server was used here, you can register multiple servers in Prometheus and manage them together in Grafana.
For very small setups, running Prometheus and Grafana directly on the GPU server is also an option.
8. Extras
Although not covered in detail, the following are useful from an operations perspective.
| Multiple GPU servers | Simply add more IPs under targets in prometheus.yml. |
| Alert settings | Forward conditions like DCGM_FI_DEV_GPU_TEMP > 80 to Alertmanager. |
| Data retention period | Adjust with Prometheus flag --storage.tsdb.retention.time=90d. |
| Version upgrades | Ensure DCGM version, NVIDIA driver, and exporter tag are compatible. |
9. References
- DCGM Exporter GitHub — https://github.com/NVIDIA/dcgm-exporter
- NVIDIA Docs — https://docs.nvidia.com/datacenter/c...-exporter.html
- Prometheus Install — https://prometheus.io/docs/prometheu.../installation/
- Grafana Install — https://grafana.com/docs/grafana/lat...lation/docker/
- Dashboard ID 12239 — https://grafana.com/grafana/dashboar...ter-dashboard/
More...